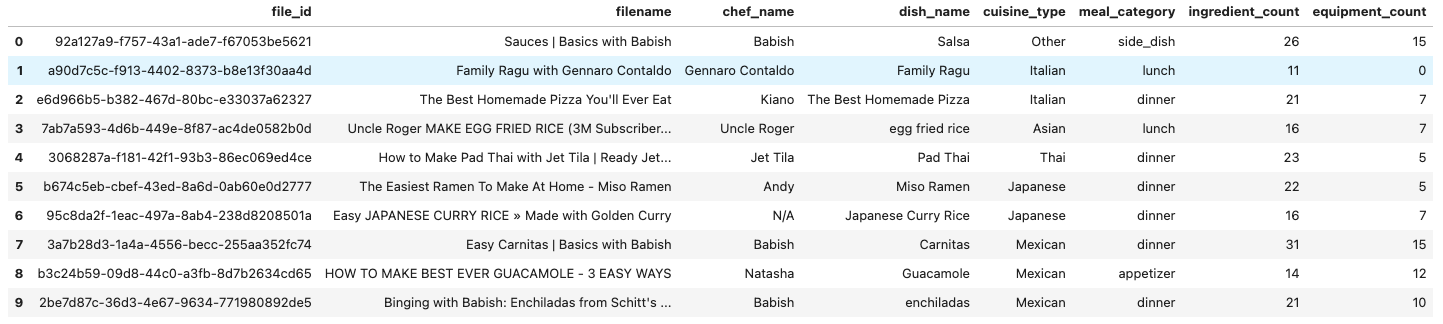
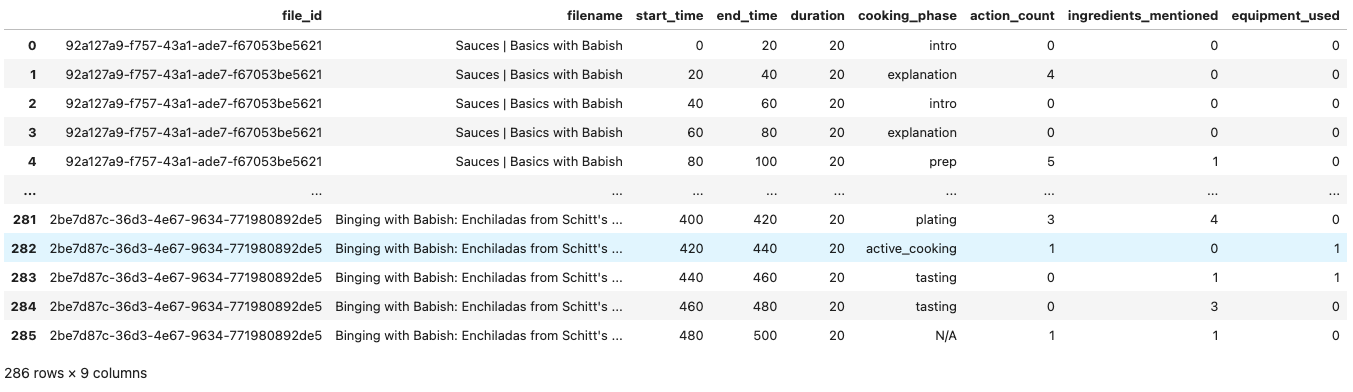
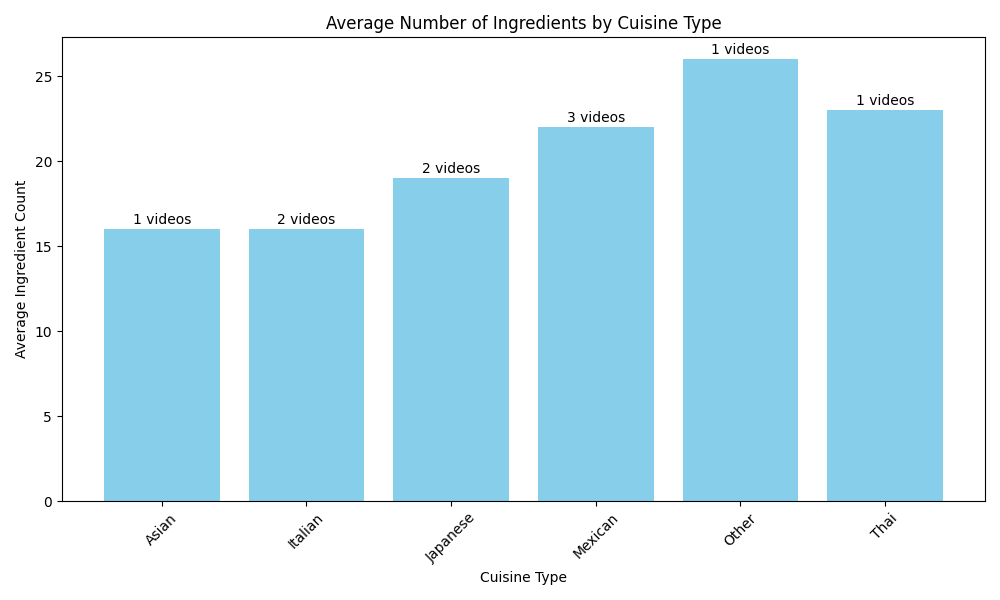
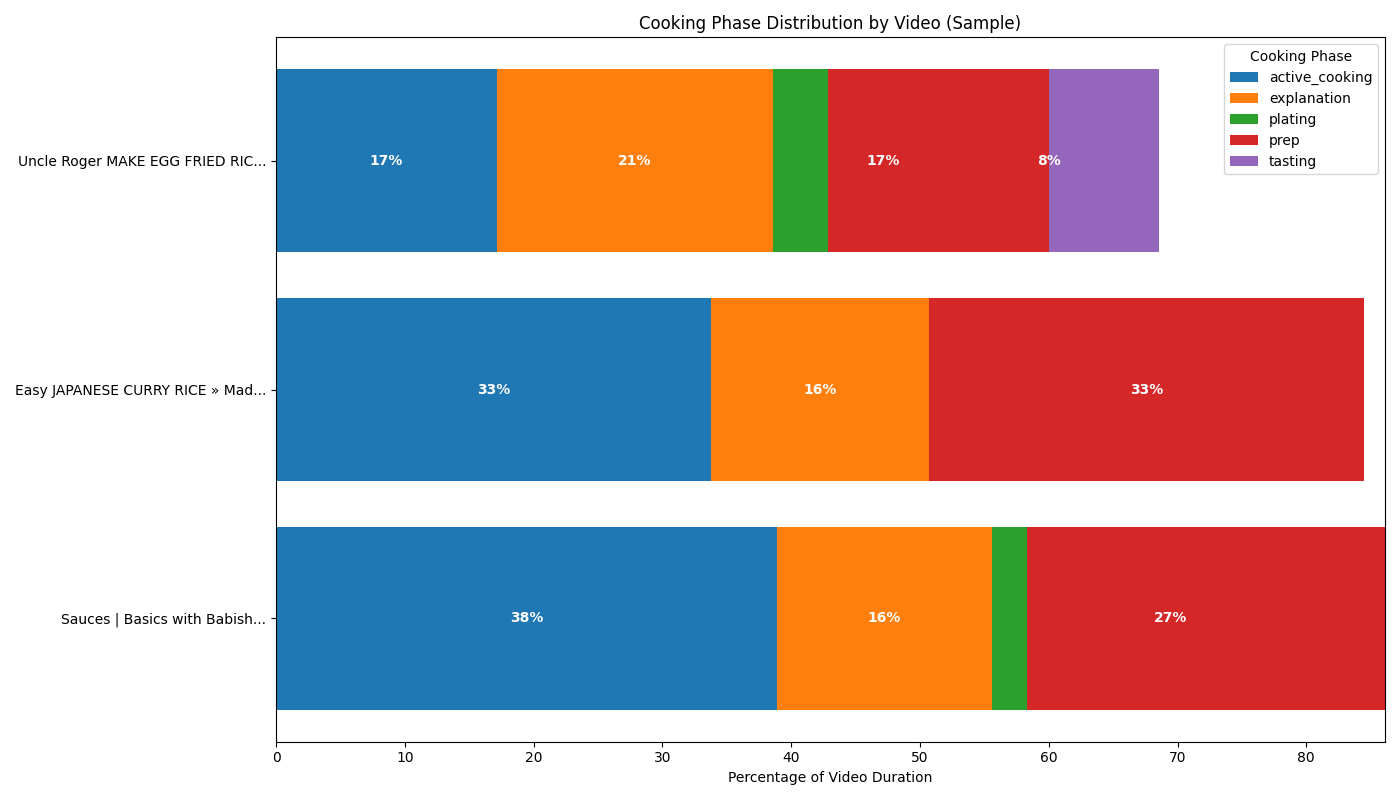
# Define our extraction schema - simplified to include only what we need for analysis
schema = {
"recipe": {
"chef_name": "string",
"dish_name": "string",
"cuisine_type": "Italian|Mexican|Asian|French|American|Mediterranean|Indian|Thai|Chinese|Japanese|Other",
"meal_category": "breakfast|lunch|dinner|snack|dessert|appetizer|side_dish"
},
"equipment_mentioned": ["string"],
"cooking_actions": ["string"],
"ingredients": ["string"],
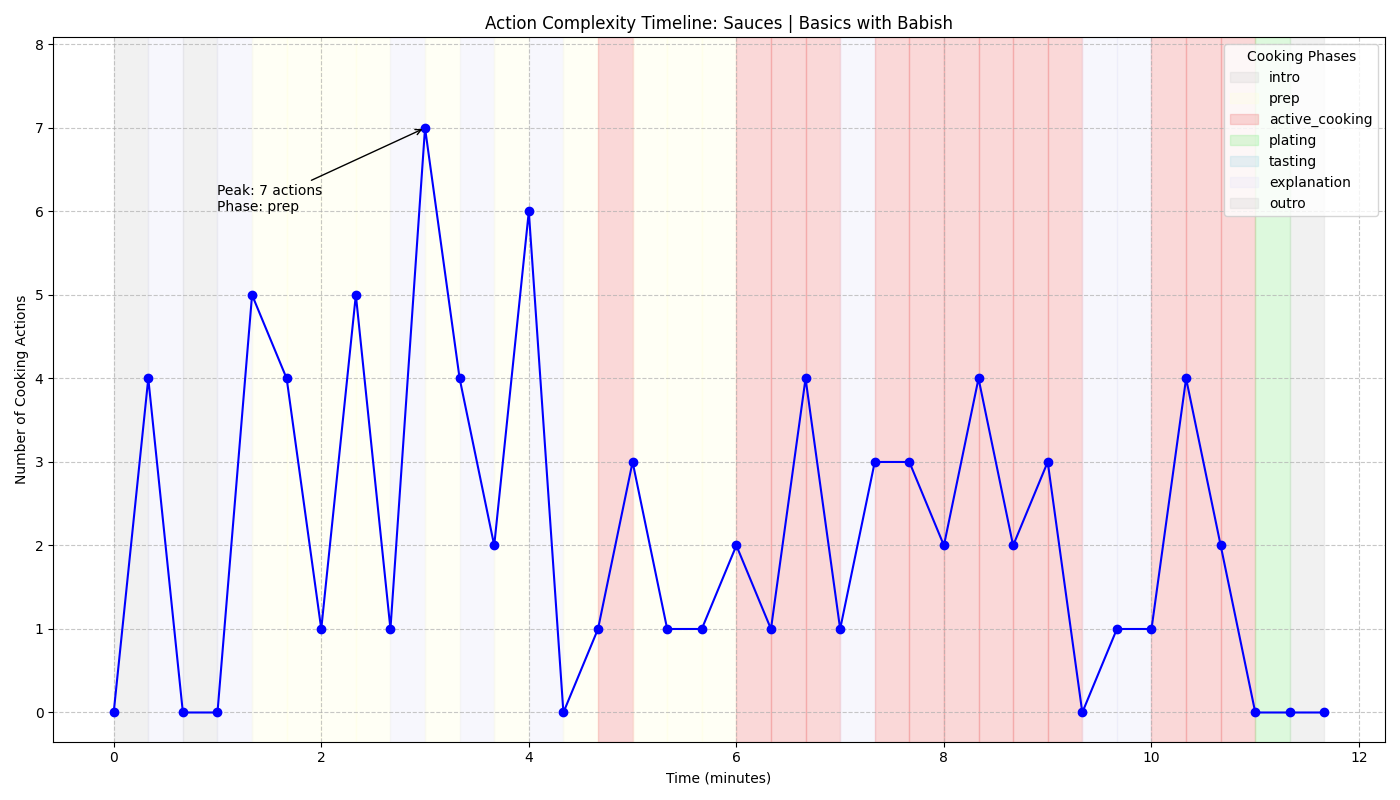
"cooking_phase": "prep|active_cooking|plating|tasting|explanation|cleanup|intro|outro"
}
# Define our extraction prompt - with precise field mappings
prompt = """
Extract cooking information from this recipe video transcript using these exact field names:
1. RECIPE (populate "recipe" object):
- chef_name: Identify the chef's name
- dish_name: Name of the dish being prepared
- cuisine_type: Choose one from: Italian, Mexican, Asian, French, American, Mediterranean, Indian, Thai, Chinese, Japanese, Other
- meal_category: Choose one from: breakfast, lunch, dinner, snack, dessert, appetizer, side_dish
2. EQUIPMENT_MENTIONED (populate "equipment_mentioned" array)
3. COOKING_ACTIONS (populate "cooking_actions" array):
- Example specific cooking action (e.g., chopping, stirring, mixing, baking, frying, etc.)
4. INGREDIENTS (populate "ingredients" array)
5. COOKING_PHASE (populate "cooking_phase" field):
- Classify the current segment as one of: prep, active_cooking, plating, tasting, explanation, cleanup, intro, outro
Focus on extracting information exactly as spoken in the transcript.
"""
# Create a collection for recipe videos
collection = client.collections.create(
name="Cooking Videos Analysis",
collection_type="entities",
description="Collection of cooking videos for recipe analysis",
extract_config={
"schema": schema,
"prompt": prompt
}
)